Mysql数据库介�绍及系统架构
再来讲讲索引下推的具体原理,先看下面这张 MySQL 简要架构图。
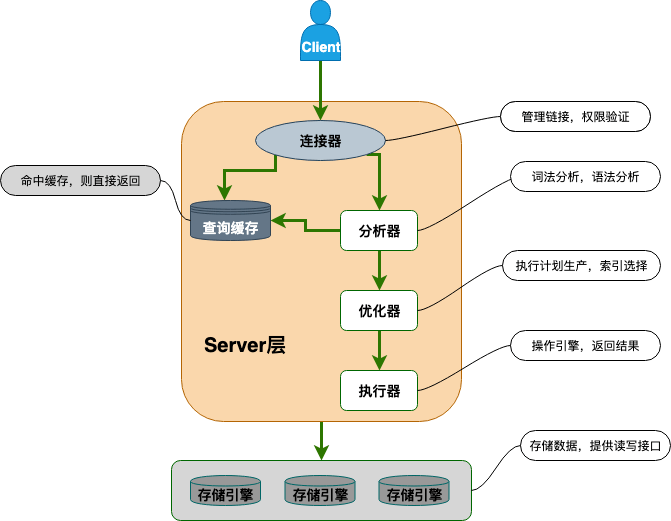
MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处理查询解析、分析、优化、缓存以及与客户端的交互等操作,而存储引擎层负责数据的存储和读取,MySQL 支持 InnoDB、MyISAM、Memory 等多种存储引擎。
索引下推的下推其实就是指将部分上层(Server 层)负责的事情,交给了下层(存储引擎层)去处理。
我们这里结合索引下推原理再对上面提到的例子进行解释。
没有索引下推之前:
- 存储引擎层先根据
zipcode索引字段找到所有zipcode = '431200'的用户的主键 ID,然后二次回表查询,获取完整的用户数据; - 存储引擎层把所有
zipcode = '431200'的用户数据全部交给 Server 层,Server 层根据MONTH(birthdate) = 3这一条件再进一步做筛选。
有了索引下推之后:
- 存储引擎层先根据
zipcode索引字段找到所有zipcode = '431200'的用户,然后直接判断MONTH(birthdate) = 3,筛选出符合条件的主键 ID; - 二次回表查询,根据符合条件的主键 ID 去获取完整的用户数据;
- 存储引擎层把符合条件的用户数据全部交给 Server 层。
可以看出,除了��可以减少回表次数之外,索引下推还可以减少存储引擎层和 Server 层的数据传输量。
最后,总结一下索引下推应用范围:
- 适用于 InnoDB 引擎和 MyISAM 引擎的查询。
- 适用于执行计划是 range, ref, eq_ref, ref_or_null 的范围查询。
- 对于 InnoDB 表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB 聚集索引,完整的记录已经读入 InnoDB 缓冲区。在这种情况下使用索引下推 不会减少 I/O。
- 子查询不能使用索引下推,因为子查询通常会创建临时表来处理结果,而这些临时表是没有索引的。
- 存储过程不能使用索引下推,因为存储引擎无法调用存储函数。